운영체제 수업때, 리틀 엔디안과 빅 엔디안의 차이에 대해서 배워본 적이 있다.
그나마 기억나는 것이라면 빅 엔디안은 리눅스에서, 리틀 엔디안은 윈도우 기반에서 쓰인다는 소리를 들었던 것 같다.
일단 자세히 알아보자.
바이트 오더 - Byte Order
바이트 오더는, 일종의 글을 읽는 방향이라고 생각하면 쉬울 것 같다.
옛날 일본 시대의 글을 오른쪽에서 왼쪽으로 읽는 방식이었다고 들었다.
반면에 한국은 왼쪽에서 오른쪽으로 읽는 방식을 취했다.
바이트 오더라는 것은 그런 의미라고 생각하면 쉽다.
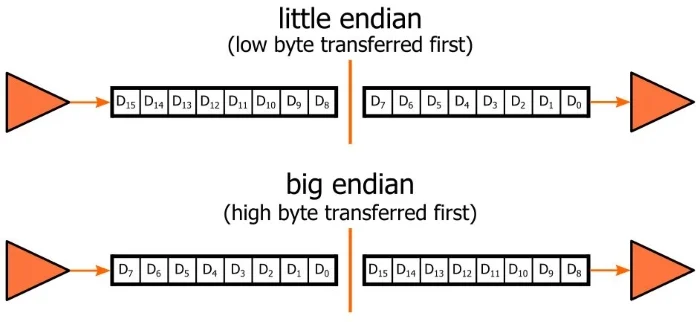
빅 엔디안은 낮은 값에서부터 시작해, 높은 값로,
리틀 엔디안은 낮은 값에서부터 시작해, 높은 값으로 쓰는 방법이다.
빅 엔디안 - Big Endian

빅 엔디안은 데이터를 저장할 때, 순차적으로 저장한다.
조금 헷갈릴 수 있는데, 왜 빅 엔디안 이냐면, 컴퓨터에서 값은 왼쪽으로 갈 수록 더욱 커진다.
만약 0x0102 가 있다면 이를 0x01, 0x02 순서로 저장할 것이고, 이 중 0x01을 최상위 비트(MSB - Most Significant Byte) 라고 부른다. 즉, 가장 왼쪽에 있는 값(MSB)를 가장 순서대로 저장하는 것이다.
리틀 엔디안
리틀 엔디안 또한 반대라고 생각하면 된다.
위의 사진에서 본 것 같이, 이번에는 최하위 비트(LSB - Least Significant Byte)로부터 저장된다.
만약에 0x010203 이런 데이터를 저장한다고 치면,
0x03, 0x02, 0x01 순서대로 저장될 것이다.
단순하게 말하자면,
데이터를 순서대로 저장한다 - 빅 엔디안
데이터를 역순으로 저장한다 - 리틀 엔디안
인 것이다.
서로의 장단점이 존재하는데, 빅 엔디안의 경우, 데이터를 읽어들일 때, 그대로 순차적으로 읽으면 된다는 점.
그래서 디버그가 편하다고 한다. 사람이 읽는 것처럼 순서 또한 같으니까 말이다.
리틀 엔디안은 가신기의 계산에 있어서 편하다고 한다. 왜냐면 최하위 비트가 맨 앞에 오므로, 다음 비트에 대한 계산이 자연스럽게 이어질 수 있다고 한다.
하지만 또 두 수의 비교를 할 때는 빅 엔디언이 더 빠르다고 한다. 최상위 비트부터 비교를 하기 때문이라고 한다.
위키백과에서는 두 방식에서 속도의 차이는 사실상 크게 차이가 나지 않는다고 하며, 상황에 맞춰 빅 엔디안이나 리틀 엔디안을 선택할 수 있게 만든 미들 엔디안도 있다고 한다.
'OS' 카테고리의 다른 글
| [OS] 페이징 (0) | 2020.10.27 |
|---|---|
| [OS] 페이지 관리 방법 (0) | 2020.09.27 |
| [OS] CPU 스케쥴링 (0) | 2020.09.18 |
| [OS] 데드락 - Deadlock (0) | 2020.09.18 |
| [OS] 프로세스와 쓰레드 (0) | 2020.09.17 |



